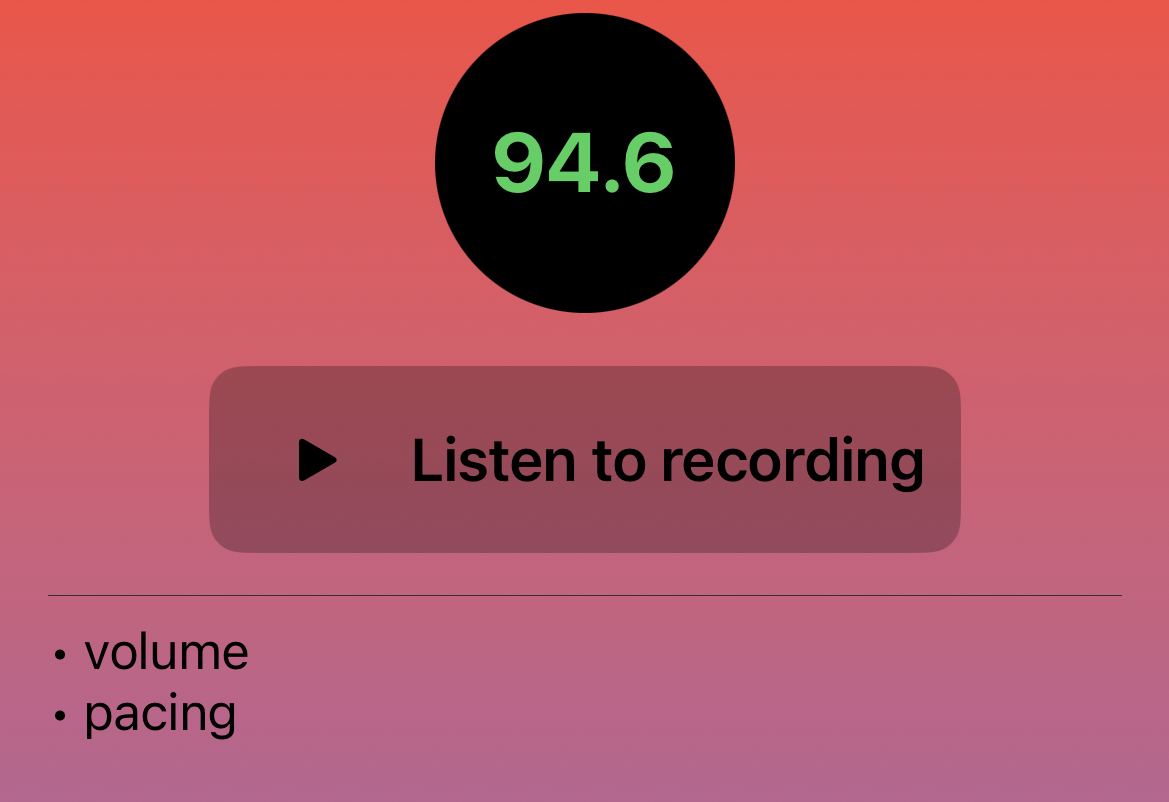
A mobile speech improvement app built
upon self-made machine learning models
A real-time speech teacher
With various front-end projects under my belt, I wanted to try my hand at mobile development.
Additonally, thermaSave had piqued my interest in machine
learning, and I wanted to dive deeper into the application of machine learning models.
Speech is something that has many attributes that can be measured and quantified such as tone,
volume, speed, etc., and I was
interested in seeing if I could build machine learning models on my own that could analyze
speech and provide feedback based on those models. Thus, the idea for helloMilo was born. Check
out
the helloMilo source code here.
(The name for helloMilo comes from 'hello' and 'Milo' - derived from the Greek word 'μιλώ'
or
'miló', which means to speak.)
Collaborated alongside Tyler Yan and Ahmet Hamamcioglu.
Tech Stack:
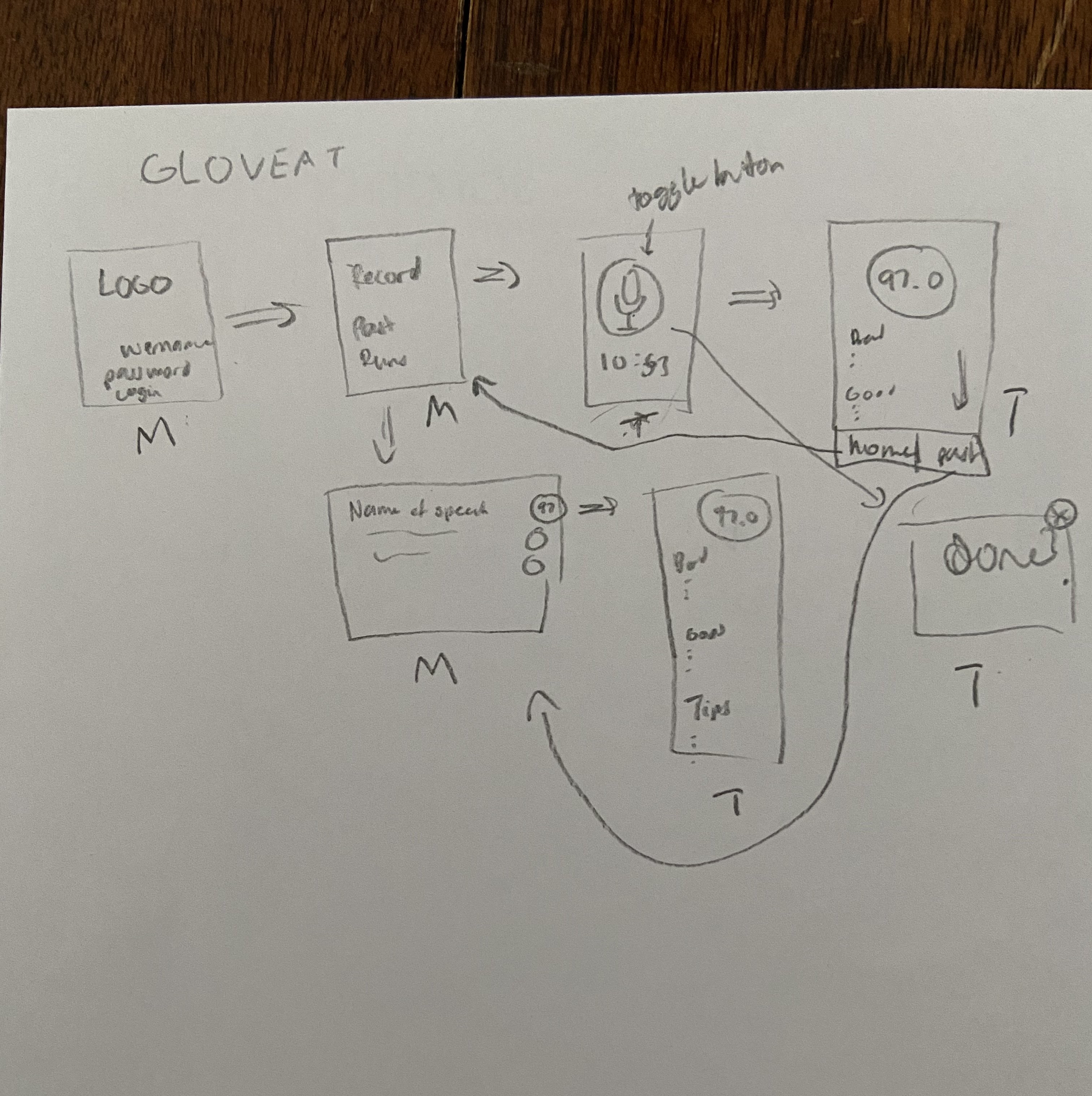
Navigating a maze
Since it was our first time undertaking a major mobile app project, we started desiging
the layout of the app (ie. how the pages would connect to each other, and where
information needed to be shared). Since I was working with a language and framework I
had never used before (Swift and SwiftUI), it took time to get up to speed with the
development of the app.
The image to the left shows the initial layout of the app, and how the pages would
connect with each other. For instance, the recording and scores screen can be seen.
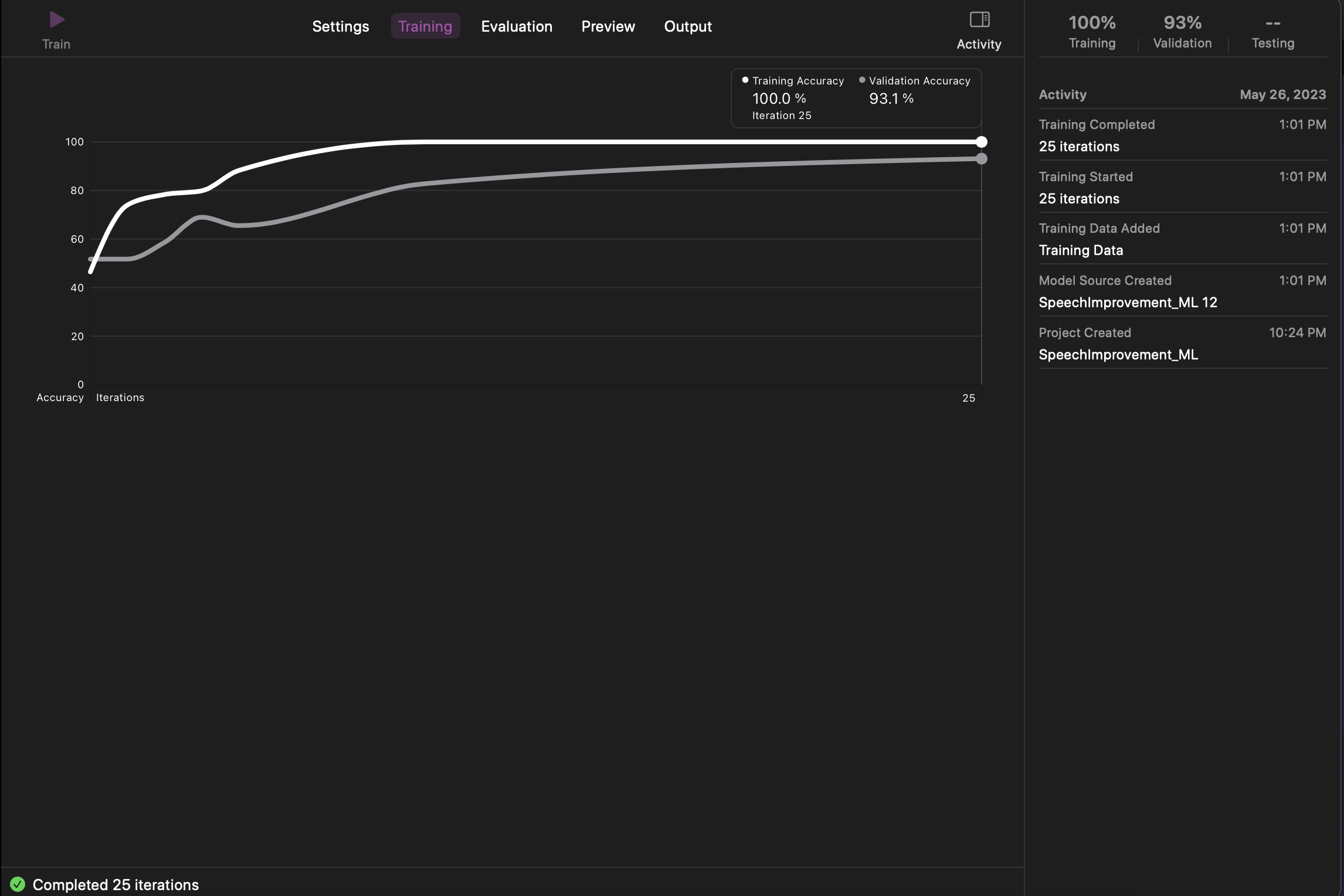
Training models
The bulk of the project hinged on getting machine learning models to accurately detect
different attributes of speech. I found that there were not many
machine learning models already available suited for speech attributes we were
looking for.
However, through Apple's machine learning development platform
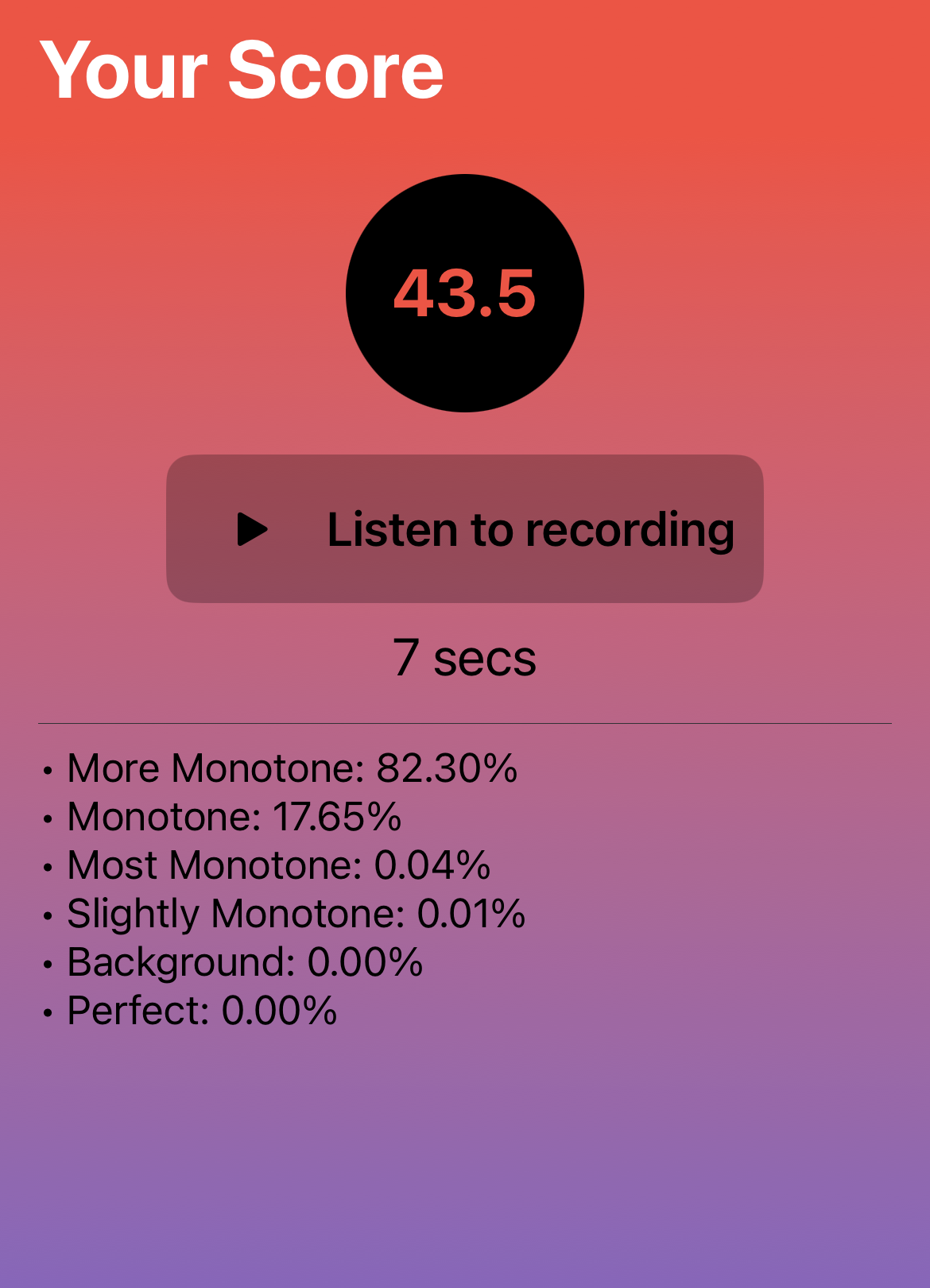
Models to Feedback
Once the models were created and their accuracy verified, the task was to apply the
models to the user's speech in real-time. The analysis worked by taking 5 second clips
at a time every 2.5 seconds, and applying the model to predict the estimated
quality of speech; this process allowed for a seamless analysis of the entire audio.
Furthermore, even though the models didn't fully know what speech was and couldn't
identify the words themselves, by taking short clips at a time, they could pick up on
general trends in tone, speed, volume, etc.
Through this process, we were able to quantitatively analyze the user's speech and give
feedback based on the quality of speech recorded. Seen right is an example of the early
stages of the scoring system, with more monotone speech being scored lower.
Future Development Steps
While the process of creating models and using them to provide feedback was quite
straightforward, the actual formation of the models was very time-intensive because a variety of
clips were needed for each speech attribute. For the tone audio classifier model alone, more
than 60 audio clips were used. Since there is no central database for these audio clips
categorized by the quality of speech, many clips are simply found by looking at various videos
through trial and error. As a result, not all speech attribute models have been fully completed.
The main priority in the future is to completely finish the remaining models.
In addition, saving user information in the cloud would enable for more personalized feedback
based on prior recordings. This would be a great way to track progress and provide more accurate
feedback.